Re-Thinking Inverse Graphics With Large Language Models
Peter Kulits*, Haiwen Feng*, Weiyang Liu, Victoria Abrevaya, Michael J. Black
TMLR; ICLR 2025 Journal Track
![]()
![]()
![]()
![]()
![]()
Summary
We present the Inverse-Graphics Large Language Model (IG-LLM) framework, a general approach to solving inverse-graphics problems. We instruction-tune an LLM to decode a visual (CLIP) embedding into graphics code that can be used to reproduce the observed scene using a standard graphics engine. Leveraging the broad reasoning abilities of LLMs, we demonstrate that our framework exhibits natural generalization across a variety of distribution shifts without the use of special inductive biases.
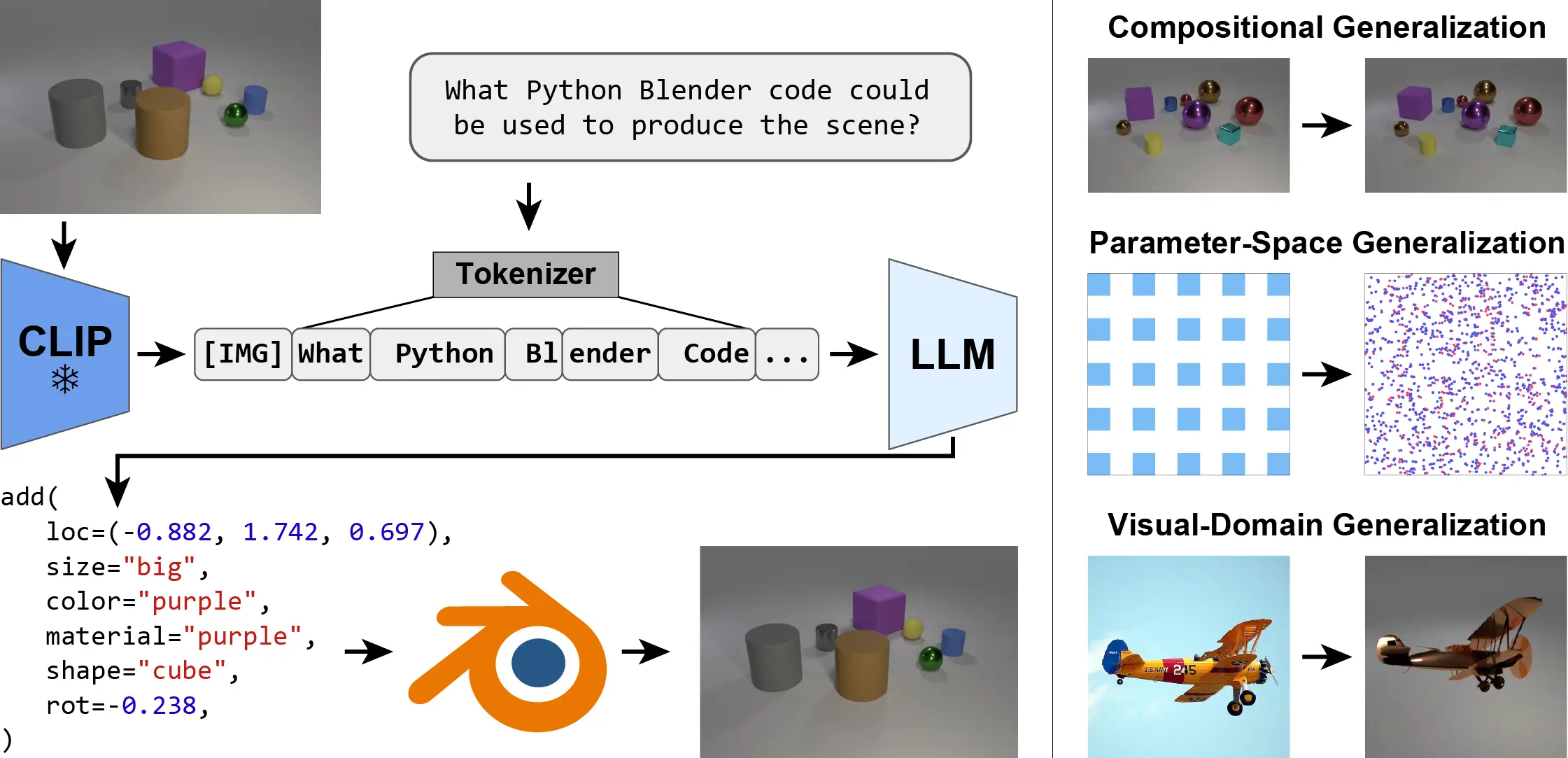
Goal
Generate a graphics program from a single image that can reproduce an observed 3D scene and its constituent objects using a traditional graphics engine.
Problem
However, this task is very ill-posed, as many possible 3D scenes could produce any given image. Disentangling an image into its constituent elements -- such as the shape, color, and material properties of the objects within the 3D scene -- requires a comprehensive understanding of the environment. Prior approaches rely heavily on task-specific inductive biases, which limit their ability to generalize.
Solution
Leverage the broad reasoning abilities of LLMs to enhance generalization.
Paper
|
|
AbstractInverse graphics -- the task of inverting an image into physical variables that, when rendered, enable reproduction of the observed scene -- is a fundamental challenge in computer vision and graphics. Successfully disentangling an image into its constituent elements, such as the shape, color, and material properties of the objects of the 3D scene that produced it, requires a comprehensive understanding of the environment. This complexity limits the ability of existing carefully engineered approaches to generalize across domains. Inspired by the zero-shot ability of large language models (LLMs) to generalize to novel contexts, we investigate the possibility of leveraging the broad world knowledge encoded in such models to solve inverse-graphics problems. To this end, we propose the Inverse-Graphics Large Language Model (IG-LLM), an inverse-graphics framework centered around an LLM, that autoregressively decodes a visual embedding into a structured, compositional 3D-scene representation. We incorporate a frozen pre-trained visual encoder and a continuous numeric head to enable end-to-end training. Through our investigation, we demonstrate the potential of LLMs to facilitate inverse graphics through next-token prediction, without the application of image-space supervision. Our analysis enables new possibilities for precise spatial reasoning about images that exploit the visual knowledge of LLMs. We release our code and data to ensure the reproducibility of our investigation and to facilitate future research. BibTeX@article{
|
